Pillar 1: Security Architecture
(Constrain agency, reduce impact, and prevent probabilistic outputs from becoming unsafe actions)
Security is the first pillar for a reason: once a system becomes agentic, it is no longer “just generating text.” It is interpreting instructions, selecting tools, and potentially changing external state. That turns the security problem from “model safety” into systems security, with an additional complication: the system’s reasoning layer is probabilistic, but its actions can be deterministic and irreversible.
The security objective of an agentic system is therefore not “make the model impossible to manipulate.” That is not realistic. The objective is:
Assume the reasoning layer can be influenced, and architect the system so that influence cannot easily translate into harmful actions.
This is an impact-reduction mindset. The UK NCSC makes this point forcefully in their analysis of prompt injection: prompt injection is not the same as SQL injection, and if we treat it as such we will build the wrong mitigations. The right response is designing systems that reduce risk and reduce impact when the model is manipulated.
This pillar is organized around the major security surfaces introduced by agents: communication boundaries, tool actuation, privilege separation, secrets, and inter-agent trust. It uses the classical CIA triad — Confidentiality, Integrity, Availability — as an organising lens, but with a weighting that reflects the unique properties of agentic systems:
- Integrity is the dominant concern. When a probabilistic reasoning layer can select tools and trigger real-world actions, the central security question is: can we trust that the action the system is about to take is the action it should take? Prompt injection, tool misuse, privilege escalation, and unvalidated outputs are all integrity failures. Most of this pillar's controls exist to protect integrity.
- Confidentiality maps directly to secrets management, context handling, and data exfiltration controls. Agentic systems assemble context dynamically and may pass sensitive data through model calls, making confidentiality a design-time concern rather than just an operations concern.
- Availability is less dominant than in traditional systems, but carries a specific agentic risk: the model itself is a critical dependency. If the LLM provider is unavailable, the agent's reasoning layer is offline. Rate limiting, budget controls, and graceful degradation patterns address availability.
5.1 Threat Model: What Changes When a System Becomes Agentic
CIA mapping: Integrity (instruction manipulation, tool misuse), Confidentiality (data exfiltration), Availability (denial of service, runaway loops)
Agentic systems expand the attack surface in ways that traditional LLM applications do not:
-
Instruction manipulation: user inputs, retrieved content, and tool outputs can contain adversarial instructions (prompt injection).
-
Tool misuse and unsafe actuation: the agent may be induced to call tools in unsafe ways (write actions, deletions, escalation).
-
Data exfiltration through prompts and context: sensitive data may be included in context, logged, or transmitted.
-
Denial of service and runaway autonomy: attackers (or accidents) can trigger long tool loops, excessive token usage, or resource starvation.
-
Supply chain risks in skills/tools: agents depend on tool servers, plugins, prompt templates, and “skills” that can be compromised.
OWASP’s Top 10 for LLM applications provides a useful baseline taxonomy for these threats (e.g., prompt injection, insecure output handling, model denial of service, supply chain).
A practical consequence is that agent security must be treated as multi-layered controls, not a single prompt or filter.
5.2 Boundary and Communication Controls (Human ↔ Agent ↔ Agent)
Primary CIA dimension: Confidentiality and Availability
The first security boundary is not “the model.” It is the interfaces through which an agent can be influenced. Either immediately or later through malicious or inaccurate context.
Key controls:
1) Authenticate and authorize every entry point
-
Who can message the agent?
-
Which channels are allowed (chat UI, API, events, schedules)?
-
Which identities can trigger actions vs ask questions?
2) Separate “informational” from “actionable” requests
Treat action requests as privileged operations. Even if they arrive as natural language, they should be routed through stricter policy gates before any tool call is permitted.
3) Rate limiting and abuse controls
Agent loops can be exploited for:
-
spam
-
resource consumption
-
repeated tool calls
-
context bloat leading to high spend
OWASP explicitly calls out model denial of service and resource-driven attacks as a risk class, which maps directly to rate limiting and quotas at the boundary.
Availability in agentic systems also includes a dependency that traditional systems do not have: the model itself. If the LLM provider is unavailable, the agent's reasoning layer is offline and the system cannot decide or act. Graceful degradation, fallback behaviour, and provider-failover strategies should be designed in — not treated as an afterthought.
4) Treat retrieved content as hostile by default
In agentic systems, “inputs” are not only user messages. They include:
-
retrieved web pages
-
documents
-
emails
-
tool outputs
-
other agents’ messages
This is exactly why prompt injection is so persistent: it often arrives embedded inside content the agent was supposed to read. NCSC’s framing is that treating prompt injection like SQL injection leads to false confidence; you must design around the assumption that the system can be influenced and focus on reducing downstream impact.
5.3 Privilege Separation and Control-Plane Patterns (Master–Junior + Supervisor Gates)
Primary CIA dimension: Integrity
Privilege separation is one of the most powerful agent-security patterns because it converts “the model is compromised” into “the model is constrained.”
In practice:
-
A control-plane agent (Master / Supervisor) defines policies, tool permissions, budgets, and rules.
-
One or more execution-plane agents (Junior / Worker) perform tasks with constrained privileges.
-
End users interact with the constrained agent(s), not the control-plane.
This is the agentic equivalent of separating “admin” from “runtime.”
Why this matters: OWASP defines “Excessive Agency” as a vulnerability category—damaging actions performed in response to ambiguous or manipulated model outputs—and lists excessive permissions and autonomy as root causes. Privilege separation and supervisory gates are direct mitigations for this category.
A practical pattern that scales well is:
Trigger → Decide → Act → Verify, where the Decide step can be probabilistic, but the Act step is gated by deterministic policy checks (and often human approval for high-risk actions).
OpenAI’s own guidance for MCP-enabled environments makes the same point operationally: require human confirmation for irreversible operations and validate inputs server-side even if the model produced them.
5.4 Tool Safety, Sandboxing, and Execution Risk
Primary CIA dimension: Integrity
Tool access is the most important security boundary in an agentic system because tools are how an agent converts language into impact.
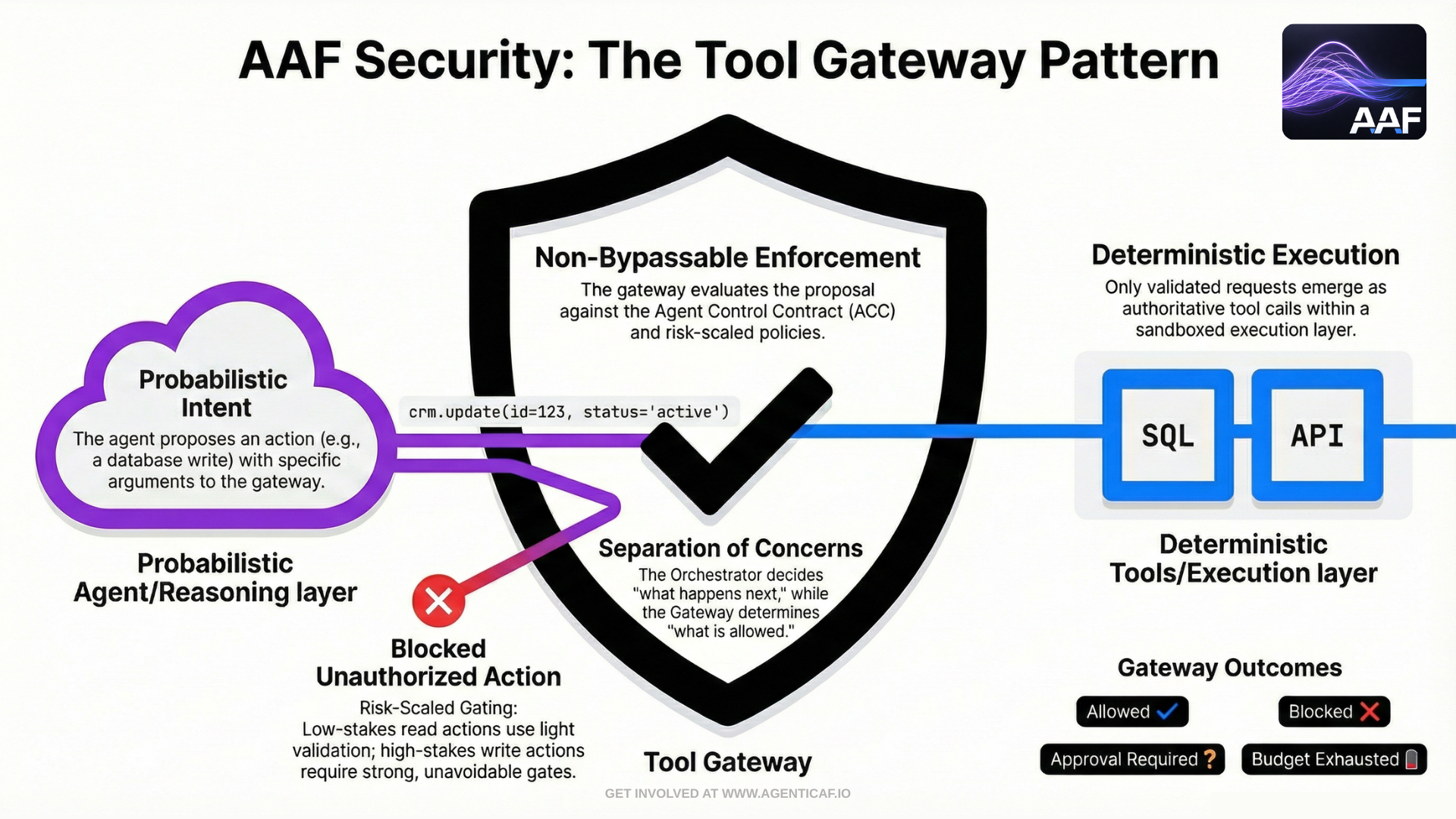
Non-bypassable Tool Gateway (required architectural boundary)
In practice, “tool safety” only holds if there is a single, non-bypassable enforcement point for tool actuation. This framework therefore assumes a Tool Gateway pattern: every tool invocation—read, write, or irreversible—must flow through a gateway that enforces policy, budgets, approvals, and auditability.
A useful mental model is to treat the gateway as the control plane for actuation:
- The agent (or orchestrator) proposes an action (“call tool X with arguments Y”).
- The gateway evaluates that proposal against binding constraints (ACC, identity, scopes, risk class, budgets).
- The gateway returns one of: allowed, blocked, approval_required, or budget_exhausted.
- Only if allowed does execution proceed in the sandbox / connector layer.
This pillar therefore assumes:
Tools represent actuation, and actuation must be treated with the same caution as arbitrary code execution.
This distinction matters because it separates probabilistic intent from deterministic enforcement. Even a manipulated agent should be unable to execute disallowed actions because the gateway enforces least privilege, server-side argument validation, and risk-scaled gates by design.
The MCP specification states this explicitly: tools represent arbitrary code execution and must be treated with appropriate caution, and tool descriptions/annotations should be treated as untrusted unless obtained from a trusted server. It also requires explicit user consent before invoking any tool.
Concrete controls:
1) Least privilege by tool and by action class
-
“Read” tools should be isolated from “write” tools.
-
“Write” tools should be further tiered: reversible vs irreversible.
-
High-risk tools should require stronger gates.
2) Sandboxing at the right layer, not just “when running shell commands”
A common mistake is sandboxing only the obvious execution surface (shell tool), while leaving other execution surfaces outside the sandbox: hooks, scripts in “skills,” tool server processes, local process spawning, etc.
NVIDIA’s security guidance for sandboxing agentic workflows highlights this precise failure mode: many systems sandbox tool invocation but leave other agentic functionality outside the sandbox, creating execution risk pathways.
3) Server-side validation of tool inputs
Never assume the model’s tool arguments are safe or correct. Validate:
-
schema and types
-
allowable ranges
-
tenant boundaries
-
file paths
-
URLs and domains
-
command allowlists
This is directly aligned with OpenAI’s security guidance for MCP-enabled apps: validate inputs server-side even if the model produced them.
4) Evidence-based “definition of done” for write actions
A secure system should require proof of action completion (and correctness) before proceeding to downstream steps. For example:
-
verify a record was updated
-
verify a deployment succeeded
-
verify a file exists and matches expected checksum
This converts “the model believes it did it” into “the system verified it.”
5.5 Secrets Management and Sensitive Data Controls
Primary CIA dimension: Confidentiality
Agentic systems increase secret risk because they:
-
assemble context dynamically,
-
may persist memory,
-
may log intermediate steps,
-
and may pass sensitive data through model calls.
A secure agent design therefore treats secrets as externalized and ephemeral:
-
Store secrets in a vault.
-
Fetch secrets just-in-time for the specific tool call.
-
Prefer short-lived credentials and scoped tokens.
-
Never place secrets in prompts or memory.
At the protocol level, MCP explicitly warns that tool descriptions should be treated as untrusted unless from a trusted server and emphasizes access controls and tool safety.
Practically, this reinforces the need for:
-
secure tool server trust models,
-
careful tool registration,
-
and explicit approval for tool invocation in high-risk settings.
5.6 Prompt Injection: From “Prevention�” to “Impact Reduction”
Primary CIA dimension: Integrity
Prompt injection is best treated as a structural risk rather than a bug you patch once.
NCSC’s guidance is useful here because it reframes the problem: prompt injection is not equivalent to SQL injection, and building mitigations as if it were will leave systems exposed.
The architecture implications:
1) Enforce instruction hierarchy and minimize trust in external content
-
System instructions must not be overridable by user/retrieved content.
-
External content should be labeled and treated as “data,” not “instructions.”
2) Constrain tool access and require policy gates
Even if the model is convinced to do something harmful, it should be unable to:
-
access privileged tools,
-
escalate scope,
-
or perform irreversible actions without human approval.
3) Avoid “direct action” patterns
A common failure mode is “LLM output → immediate execution.”
Instead, outputs should pass through epistemic gates:
-
validation checks
-
policy checks
-
approval where risk is high
OWASP’s prompt injection and excessive agency categories map directly to these design choices: they warn about manipulated inputs altering behavior and about damaging actions triggered by ambiguous/manipulated outputs.
5.7 Inter-Agent Trust Boundaries (A2A/MCP-Aware Security)
Primary CIA dimension: Integrity and Confidentiality
As organizations scale, agents will increasingly talk to other agents. That introduces a second class of boundary risk: agent-to-agent coercion.
Key requirements:
-
Authenticate agent identities and restrict which agents can request which tasks.
-
Treat incoming agent messages as untrusted inputs, just like user inputs.
-
Enforce per-agent permission scopes and budgets.
-
Prevent “context flooding” as an exfiltration vector (limit the amount and type of information any agent can request or transmit).
The MCP specification provides a strong baseline here: tools represent arbitrary execution and require explicit user consent; tool descriptions should be treated as untrusted unless from a trusted server. The same logic applies to agents.
Additionally, MCP security best practices and third-party security engineering reviews emphasize inspecting tool servers, avoiding untrusted tool servers, and thinking carefully about client behavior (e.g., name collisions, untrusted tool output).
5.8 Security as “Epistemic Gatekeeping”
Primary CIA dimension: Integrity
This pillar connects directly back to the architecture of epistemic gates introduced earlier.
The security failure mode in agentic systems is often not “the model hallucinated.” It is:
A probabilistic output crossed an epistemic gate without validation and gained authority as an action.
Security architecture is therefore the discipline of making those gates explicit and unavoidable:
-
restrict who can ask for actions,
-
restrict what actions are possible,
-
verify actions deterministically,
-
require human approval where appropriate,
-
and constrain autonomy with budgets and policy.
This is what turns “AI system” into “governed agentic system.”
5.11 Design Recommendations & Trade-offs
Key recommendations
- Provide the minimum sufficient context for the task, in a controlled and explainable form, while preserving verification signals and preventing unsafe information flow.
- Grant the minimum necessary autonomy for a task and constrain it with explicit policy gates, least-privilege tool access, and mandatory verification for write actions.
- Apply rate limiting and quotas at the agent's communication boundary to mitigate resource-driven attacks.
Cross-pillar trade-offs
- Security x Context: Providing insufficient context can lead to unsafe tool use, while providing excessive context increases the risk of data leakage and instruction injection. Provide the minimum sufficient context for the task, in a controlled and explainable form, while preserving verification signals and preventing unsafe information flow. (source: 11.1)
- Security x Autonomy: Increasing an agent's level of autonomy without sufficient governance controls like permissions and policy gates creates the 'Excessive Agency' security vulnerability. Grant the minimum necessary autonomy for a task and constrain it with explicit policy gates, least-privilege tool access, and mandatory verification for write actions. (source: 4.2.B)
- Security x Cost: A lack of security controls, such as rate limiting, makes an agent vulnerable to denial-of-service or runaway loops that cause excessive, uncontrolled costs. Apply rate limiting and quotas at the agent's communication boundary to mitigate resource-driven attacks. (source: 5.1)
By autonomy level
- Assistive:
- Security x Context: Oversized context may surface sensitive data in suggestions or omit security constraints, leading to unsafe human decisions.
- Security x Autonomy: Risk is low — the human remains the actuator, but the agent's suggestions can still influence unsafe decisions.
- Security x Cost: Repeated queries can drive up inference costs even without action execution — apply rate limiting.
- Delegated:
- Security x Context: Malicious instructions hidden in context can shape proposed plans; sensitive data may leak in plan details.
- Security x Autonomy: Security depends on the human approver catching manipulated or damaging proposed actions.
- Security x Cost: Repeated plan submissions consume resources regardless of approval outcome — throttle submission frequency.
- Bounded Autonomous:
- Security x Context: Excess untrusted context increases prompt injection risk; insufficient context leads to unsafe tool arguments.
- Security x Autonomy: Highest risk — an agent with excessive autonomy can be manipulated into harmful actions without a human-in-the-loop gate.
- Security x Cost: A triggered runaway loop causes significant financial damage before detection — enforce per-loop budget caps.
- Supervisory:
- Security x Context: Context-passing between agents can become a data exfiltration channel or a vector for cascading injection attacks.
- Security x Autonomy: A supervisory agent with excessive autonomy can mismanage workers, escalate permissions, or approve harmful actions at scale.
- Security x Cost: A single compromised worker entering a costly loop can exhaust the shared budget for the entire agent team.
Section 5 Citations (Sources & Links)
-
UK NCSC: Prompt injection is not SQL injection (it may be worse)
https://www.ncsc.gov.uk/blog-post/prompt-injection-is-not-sql-injection
-
UK NCSC: Mistaking AI vulnerability could lead to large-scale breaches
https://www.ncsc.gov.uk/news/mistaking-ai-vulnerability-could-lead-to-large-scale-breaches -
OWASP: Top 10 for Large Language Model Applications
https://owasp.org/www-project-top-10-for-large-language-model-applications/
-
OWASP: Top 10 for LLM Applications (2025 PDF)
https://owasp.org/www-project-top-10-for-large-language-model-applications/assets/PDF/OWASP-Top-10-for-LLMs-v2025.pdf -
OWASP GenAI Security Project: LLM01 Prompt Injection
-
OWASP GenAI Security Project: Excessive Agency (category, triggers, root causes) https://genai.owasp.org/llmrisk2023-24/llm08-excessive-agency/”
-
Model Context Protocol: Specification (Tool Safety + explicit user consent; tool annotations untrusted unless trusted server)
https://modelcontextprotocol.io/specification/2025-11-25 -
Model Context Protocol — Tools (server/tools): annotations treated as untrusted unless from trusted servers
https://modelcontextprotocol.io/specification/2025-06-18/server/tools
-
OpenAI Developers: Apps SDK: Security & Privacy (prompt injection + write actions; server-side validation; human confirmation)
https://developers.openai.com/apps-sdk/guides/security-privacy/
-
NVIDIA Developer Blog: Practical security guidance for sandboxing agentic workflows and managing execution risk
https://developer.nvidia.com/blog/practical-security-guidance-for-sandboxing-agentic-workflows-and-managing-execution-risk/ -
Semgrep: A security engineer’s guide to MCP (client-side concerns: untrusted tool descriptions/output, first-run approval, name collisions)
https://semgrep.dev/blog/2025/a-security-engineers-guide-to-mcp
-
Model Context Protocol — Security best practices (draft)
https://modelcontextprotocol.io/specification/draft/basic/security\_best\_practices